Comment déployer un model d'IA local intégré à VScodium¶

1. Installation¶
- Installer Ollama:
curl -fsSL https://ollama.com/install.sh | sh- Télécharger le modèle:
ollama pull llama3:latest- Lancer le modèle:
ollama run llama3:latestLa console permet d'intéragir avec le modèle directement, pour quitter, appuyer sur Ctrl+D
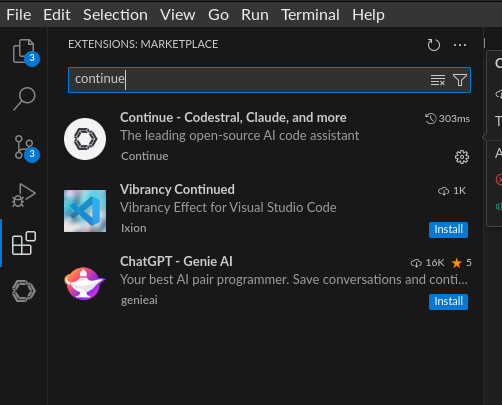
- Installer le plugin
continue:
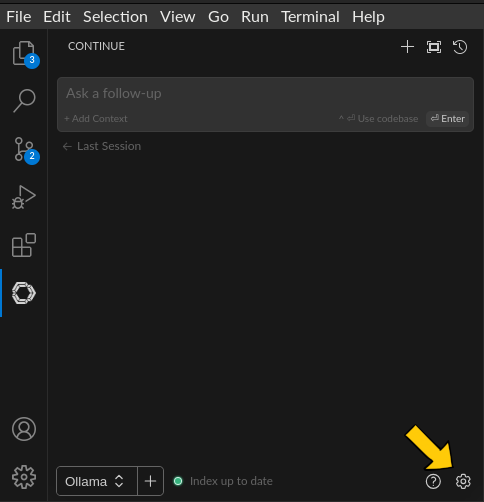
- Cliquer sur le rouage en bas à droite:
2. Configuration¶
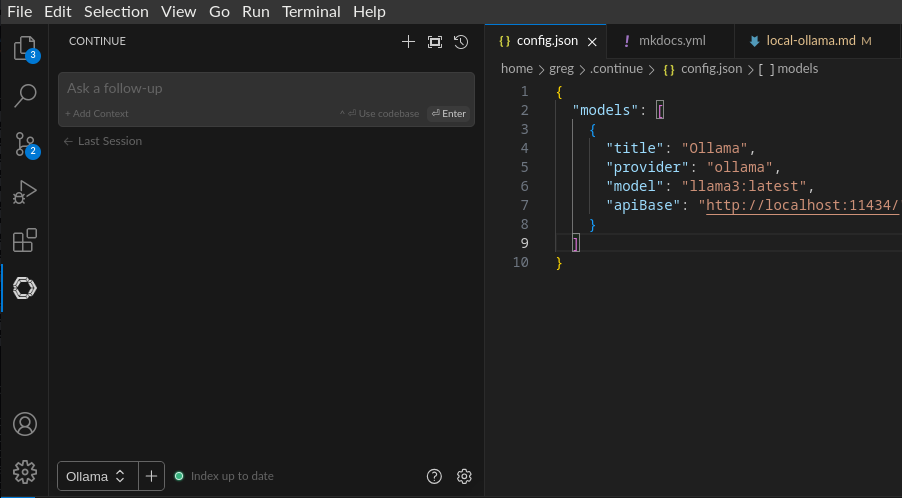
Editer le fichier config.json:
{
"models": [
{
"title": "Ollama",
"provider": "ollama",
"model": "llama3:latest",
"apiBase": "http://localhost:11434/"
}
]
}Il devrait ressembler à ça:
3. Utilisation¶
- Ouvrir le panneau latéral avec le bouton
continueet poser une question
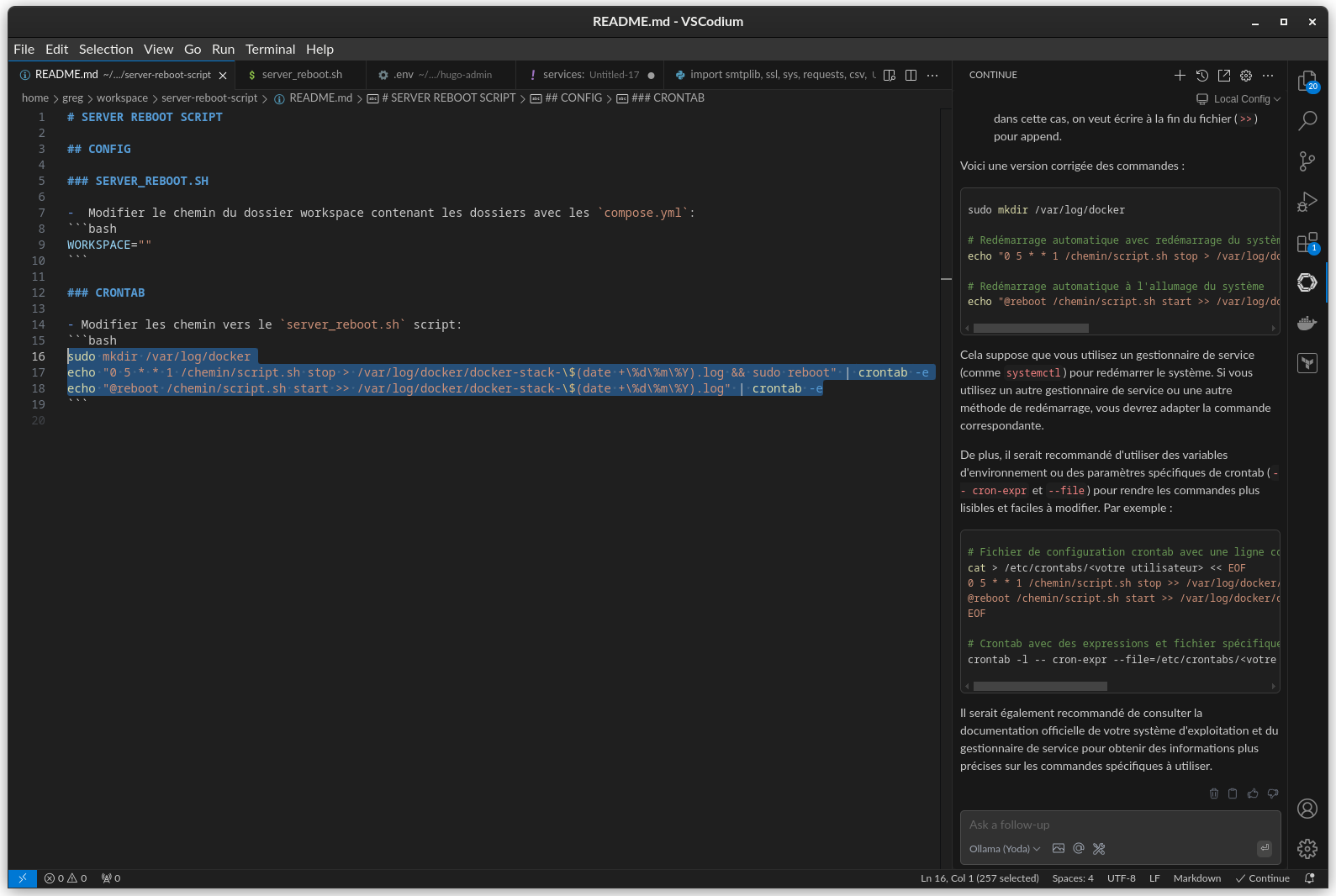
Il est possible de surligner du code et d'appuyer sur Ctrl+L pour le référençé dans la discussion avec le modèle
4. Gérer Ollama¶
- Stopper le service:
sudo systemctl stop ollama- Démarrer le service:
sudo systemctl start ollama- Supprimer un modèle:
ollama rm <MODEL>- Modèles compatibles:
- Télécharger un modèle:
ollama pull <MODEL>